Full Paper
Abstract
We explore the design of scalable synchronization primitives for disaggregated shared memory. Porting existing synchronization primitives to disaggregated shared memory results in poor scalability with the number of application threads because they layer synchronization primitives atop cache-coherence substrates, which engenders redundant inter-core communications. Substantially higher cache-coherence latency (μs) with substantially lower bandwidths in state-of-the-art disaggregated shared memory designs amplifies the impact of such redundant communications and precludes scalability.
In this work, we argue for a co-design for the cache-coherence and synchronization layers for better performance scaling of multi-threaded applications on disaggregated memory. This is driven by our observation that synchronization primitives are essentially a generalization of cache-coherence protocols in time and space. We present Soul as an implementation of this co-design. Soul employs wait queues and arbitrarily-sized cache lines directly at the cache-coherence protocol layer for temporal and spatial generalization. We evaluate Soul against the layered approach for synchronization primitives — the pthread implementation of reader-writer lock — and show that Soul improves in-memory key-value store performance at scale by 1-2 orders of magnitude.
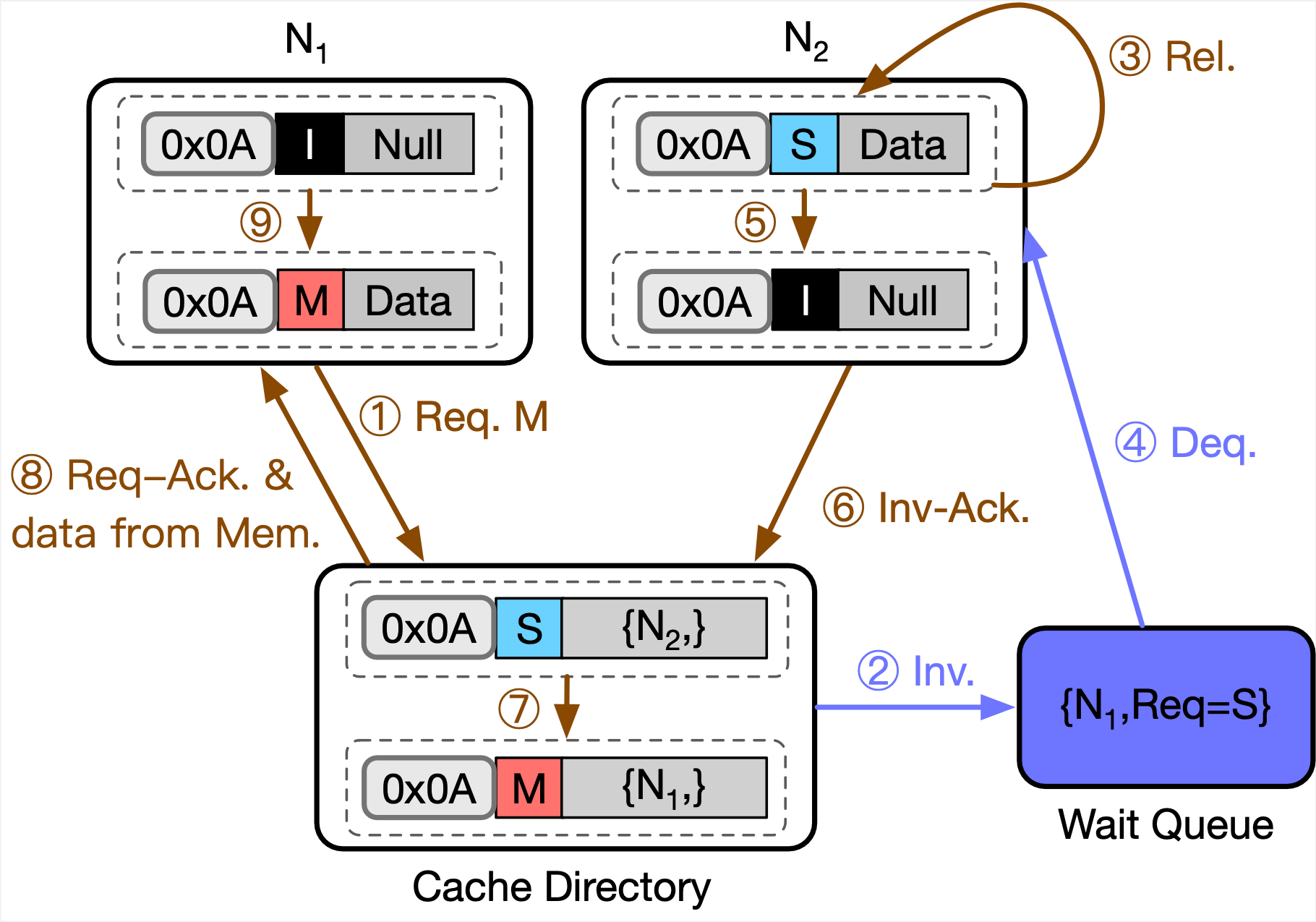 A locking example in GCP with temporal generalization. Refer to the paper for more details.
A locking example in GCP with temporal generalization. Refer to the paper for more details.